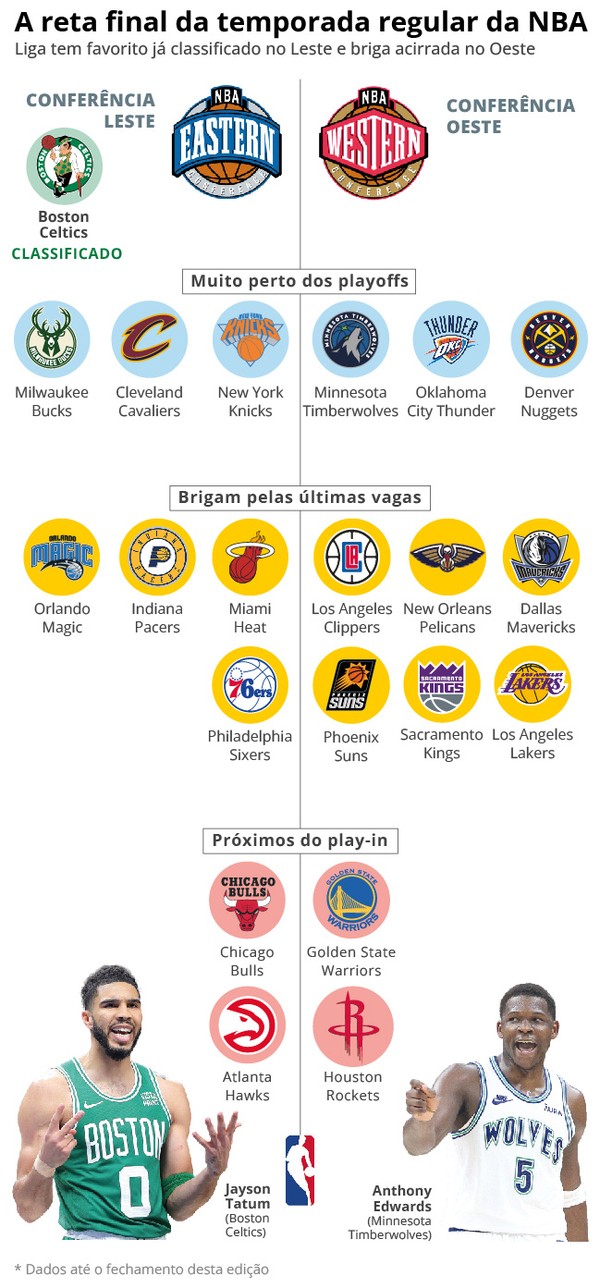
Beleza, pessoal! Hoje vou compartilhar com vocês como eu fiz para tentar prever os vencedores da temporada regular da NBA. Foi um projeto divertido e desafiador, e vou contar tudo, tim tim por tim tim.
Primeiro de tudo, precisei de dados. Fui atrás de estatísticas de temporadas anteriores, tipo: resultados dos jogos, pontos marcados, rebotes, assistências, tudo que vocês imaginarem. Peguei tudo de sites especializados em estatísticas de basquete, sabe? Demorou um bocado pra organizar tudo numa planilha, mas foi crucial.
Aí começou a parte de escolher quais dados usar. No começo, queria usar tudo, mas vi que ia virar uma bagunça. Decidi focar em algumas coisas que pareciam mais importantes: média de pontos por jogo, aproveitamento nos arremessos, rebotes totais e assistências. Também adicionei o histórico de confrontos diretos entre os times, pra ver quem costumava levar a melhor.
Com os dados na mão, precisei escolher um modelo de machine learning. Pensei em usar uma regressão logística, mas no fim das contas optei por um Random Forest. Achei que ele lidaria melhor com as diferentes variáveis e me daria um resultado mais preciso. Tive que dar uma estudada boa em como o Random Forest funciona, ajustar os parâmetros e tal, mas valeu a pena.
Depois de treinar o modelo, hora de testar! Peguei os dados da temporada anterior (que não tinham sido usados no treinamento) e joguei no modelo pra ver o que ele previa. Comparei os resultados com o que realmente aconteceu e calculei a precisão. No começo, a precisão não era lá essas coisas, tipo uns 60%. Fiquei meio frustrado, mas não desisti.
Voltei pros dados, revisei tudo, testei outras combinações de variáveis, mexi nos parâmetros do Random Forest. Depois de várias tentativas, consegui aumentar a precisão para uns 75%. Ainda não era perfeito, mas já dava pra brincar.

Com o modelo “afiado”, finalmente pude usá-lo pra prever os resultados da temporada atual. Peguei os dados disponíveis até o momento e rodei no modelo. Foi emocionante ver as previsões! Claro que eu sabia que não dava pra confiar 100%, mas foi divertido acompanhar os jogos e ver se o modelo estava acertando ou errando.
- Coleta de Dados: Juntei estatísticas de várias temporadas da NBA.
- Seleção de Variáveis: Escolhi as estatísticas mais relevantes para o modelo.
- Treinamento do Modelo: Usei o Random Forest para prever os resultados.
- Teste e Ajuste: Avaliei a precisão e ajustei os parâmetros do modelo.
- Previsões: Usei o modelo para prever os resultados da temporada atual.
Conclusões
No fim das contas, o projeto foi uma baita experiência de aprendizado. Vi na prática como funciona um projeto de machine learning, desde a coleta de dados até a aplicação do modelo. Aprendi a importância de escolher as variáveis certas, de ajustar os parâmetros do modelo e de avaliar a precisão dos resultados. E o mais importante: vi que prever o futuro é difícil, mas com os dados certos e as ferramentas adequadas, dá pra chegar perto!
Se vocês curtiram essa jornada, me contem nos comentários! E se tiverem alguma dica ou sugestão, fiquem à vontade pra compartilhar. Até a próxima!